https://chacker.pl/
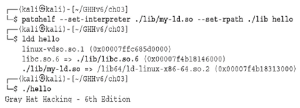
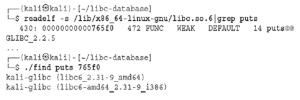
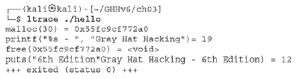
Narzędzie wiersza poleceń strace jest przydatne, gdy musimy śledzić wywołania i sygnały systemowe. Wykorzystuje wywołanie systemowe ptrace do sprawdzania programu docelowego i manipulowania nim, a poza tym, że pozwala nam lepiej zrozumieć zachowanie programu, może być również wykorzystywane do manipulowania zachowaniem wywołań systemowych w celu lepszego rozwiązywania problemów lub szybszego odtworzenia ataku w określonych warunkach sytuacjach (na przykład wprowadzenie błędu, wprowadzenie wartości zwracanej, wprowadzenie sygnału i wprowadzenie opóźnienia). Spójrzmy na kilka przykładów. Przede wszystkim upewnij się, że masz zainstalowany pakiet strace za pomocą polecenia dpkg -l strace, ponieważ domyślnie nie jest on dostarczany z Kali. Używaj sudo apt install strace, aby go zainstalować. Kiedy uruchomisz strace bez argumentów, wyświetli wszystkie wywołania systemowe i sygnały, tak jak poniżej:

Możemy użyć opcji -e trace=syscall, jeśli chcemy prześledzić/filtrować określone wywołanie systemowe, jak pokazano poniżej:

Jak zachowałby się program, gdyby funkcja zapisu nie została zaimplementowana?

Możemy również wstrzyknąć konkretną odpowiedź na błąd. Zamiast tego wstrzyknijmy błąd „EAGAIN (Zasób tymczasowo niedostępny)”:

Możliwe jest również użycie strace do wstrzykiwania opóźnień. Jest to bardzo pomocne w wielu przypadkach, ale dobrym przykładem jest sytuacja, w której musimy uczynić warunek wyścigu bardziej deterministycznym, pomagając zmniejszyć losowość wywłaszczania programu planującego. Wprowadźmy opóźnienie 1 sekundy przed wykonaniem funkcji odczytu (delay_enter) i opóźnienie 1 sekundę po wykonaniu funkcji zapisu (delay_exit). Domyślnie oczekiwana precyzja czasu to mikrosekundy:

Jeśli chcesz dowiedzieć się więcej o strace, Dmitry Levin ( przeprowadzi Cię przez listę zaawansowanych funkcji w swoim przemówieniu „Modern strace”.