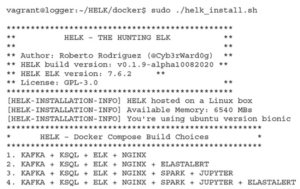
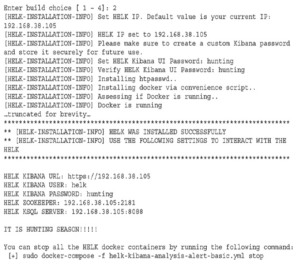
https://chacker.pl/
Jeśli nie masz dostępnych 16 GB pamięci RAM, będziesz chciał skorzystać z chmury. W tym laboratorium będziemy używać platformy Azure. Jako bonus za rejestrację otrzymasz środki w wysokości 200 USD, które należy wykorzystać w ciągu pierwszych 30 dni, czyli wystarczająco dużo czasu, aby kopnąć opony i sprawdzić, czy chcesz korzystać z laboratorium przez dłuższy czas. Jeśli jednak wolisz korzystać z AWS, repozytorium DetectionLab GitHub zawiera również łatwe instrukcje instalacji.
PRZESTROGA: Nie trzeba dodawać, że chmura nie jest bezpłatna i jeśli będziesz z niej korzystać poza posiadanymi środkami, poniesiesz znaczne opłaty. Dobra wiadomość jest taka, że możesz wyłączyć obrazy, gdy ich nie potrzebujesz, aby zaoszczędzić koszty. Zostałeś ostrzeżony. Aby to zmienić, tym razem uruchomimy nasze instancje w chmurze z hosta Mac. Ponownie obsługiwany jest każdy host; wystarczy odwiedzić witrynę DetectionLab, aby zapoznać się z innymi systemami operacyjnymi. Aby uruchomić to laboratorium w chmurze (Azure), najpierw zainstaluj Brew, Terraform, Ansible, i narzędzia interfejsu wiersza polecenia platformy Azure

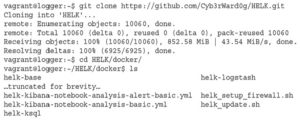
Pobierz kod źródłowy z repozytorium DetectionLab GitHub:

Skopiuj przykładowy plik tfvars i edytuj go, aby uwzględnić Twój adres IP (whatismyip.com) i informacje o lokalizacji pliku użytkownika:
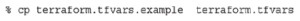
Edytuj plik za pomocą swojego ulubionego edytora. Ponownie pamiętaj o zaktualizowaniu zmiennej ip_whitelist, a także lokalizacji kluczy publicznych i prywatnych, zmieniając „/home/user” na lokalizację pokazanego wyjścia generatora kluczy. Jeśli pominiesz ten krok, dostęp do laboratoriów zostanie zablokowany, ponieważ dostęp do laboratoriów będą miały tylko adresy IP z białej listy.
NOTATKA. Jeśli w przyszłości zmienisz swój adres IP, koniecznie przejdź do Azure Portal, wyszukaj „Sieciowe grupy zabezpieczeń” u góry, znajdź swoją grupę zabezpieczeń i tam zmień swój adres IP na regułach przychodzących. Następnie edytuj plik main.tf, aby zmienić rozmiar systemu Linux (aby uwzględnić późniejsze kroki). Wyszukaj w pliku main.tf następującą sekcję i upewnij się, że ostatnia linia została zmieniona z D1 na D2, jak pokazano:

Teraz skonfiguruj swoje konto Azure, jeśli jeszcze tego nie zrobiłeś. Jeśli masz już tam darmowe konto lub zostaniesz o to zapytany podczas rejestracji, będziesz musiał wybrać opcję Pay As You Go, ponieważ ta opcja jest wymagana do zwiększenia limitu procesora i pozwala na uruchomienie wymaganego rozmiaru i liczby maszyn laboratorium. W chwili pisania tego tekstu nadal będziesz otrzymywać kredyt w wysokości 200 USD do wykorzystania w pierwszym miesiącu (na przykład moje testy wykazały około 12,16 USD dziennie podczas opracowywania tego laboratorium). Tak długo, jak zamkniesz laboratoria, kiedy z nich nie korzystasz, powinieneś mieć mnóstwo korzyści z tego kredytu w wysokości 200 USD. Pamiętaj, jak wspomniano wcześniej, musisz zdawać sobie sprawę z kosztów przekraczających kwotę kredytu w wysokości 200 USD i odpowiednio je monitorować.
NOTATKA. Jeśli zapomnisz wybrać płatność zgodnie z rzeczywistym użyciem lub później pojawi się następujący błąd, konieczne będzie przejście do rozliczeń i przejście na opcję płatności zgodnie z rzeczywistym użyciem:
I Error: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=0 – Original Error: autorest/azure: Service returned an error. Status=<nil> Code=“OperationNotAllowed” Message=“Operation could not be completed as it results in exceeding approved Total Regional Cores quota. Additional details …
Więcej informacji na temat limitów przydziałów można znaleźć na stronie https://docs.microsoft.com/en-us/azure/azure-supportability/regional-quotarequests.” Następnie, aby uwierzytelnić się przy użyciu nowego konta Azure, uruchom następujące polecenie, które uruchomi witrynę internetową umożliwiającą uwierzytelnienie na platformie Azure:
% az login
Następnie utwórz klucz SSH, którego Terraform może używać do zarządzania systemem Logger (Linux), jak pokazano poniżej. Pamiętaj, aby nadać nowemu kluczowi hasło.

Następnie przechowuj klucz w ssh-agent (pamiętaj, że Terraform musi uzyskać dostęp do klucza bez hasła, a ssh-agent to umożliwia):
Na koniec możesz uruchomić laboratoria z wiersza poleceń, używając następującego kodu.
Teraz możesz wyświetlić dane wyjściowe skryptów, aby zobaczyć swoje adresy IP:

Jesteś prawie gotowy! Należy dokończyć aprowizację WEF, Win10 i DC. Aby to zrobić, najpierw przejdź do katalogu Ansible:
Teraz edytuj plik Inventory.yml za pomocą swojego ulubionego edytora, aby zaktualizować wartości IP x.x.x.x każdego hosta, używając wartości public_ip z polecenia wyjściowego Terraform. Pamiętaj, aby nie usuwać wcięć, ponieważ są one ważne. Następnie uruchom podręcznik Ansible, ustawiając najpierw zmienną środowiskową, aby obejść błąd w systemie macOS za pomocą Ansible: