https://chacker.pl/
Kiedy procesy są ładowane do pamięci, są zasadniczo podzielone na wiele małych sekcji. Zajmujemy się tylko sześcioma głównymi sekcjami, które omówimy.
Sekcja .text
Sekcja .text, znana również jako segment kodu, zasadniczo odpowiada części .text binarnego pliku wykonywalnego. Zawiera instrukcje maszynowe umożliwiające wykonanie zadania. Ta sekcja jest oznaczona jako czytelna i wykonywalna, a próba zapisu spowoduje naruszenie zasad dostępu. Rozmiar jest ustalany w czasie wykonywania, kiedy proces jest ładowany po raz pierwszy.
Sekcja .data
Sekcja .data służy do przechowywania inicjowanych zmiennych globalnych, takich jak
int a = 0;
Rozmiar tej sekcji jest ustalany w czasie wykonywania. Należy go jedynie oznaczyć jako czytelny.
Sekcja .bss
Poniższa sekcja stosu (.bss) służy do przechowywania niektórych typów niezainicjowanych zmiennych globalnych, takich jak int a; Rozmiar tej sekcji jest ustalany w czasie wykonywania. Segment ten musi być czytelny i zapisywalny, ale nie powinien być wykonywalny.
Sekcja sterty
Sekcja sterty służy do przechowywania dynamicznie przydzielanych zmiennych i rośnie od pamięci o niższym adresie do pamięci o wyższym adresie. Alokacją pamięci steruje się za pomocą funkcji malloc(), realloc() i free(). Na przykład, aby zadeklarować liczbę całkowitą i przydzielić pamięć w czasie wykonywania, możesz użyć czegoś takiego:
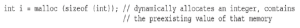
Sekcja sterty powinna być czytelna i zapisywalna, ale nie powinna być wykonywalna, ponieważ osoba atakująca, która uzyska kontrolę nad procesem, może z łatwością wykonać wykonanie kodu powłoki w obszarach takich jak stos i sterta.
Sekcja stosu
Sekcja stosu służy do śledzenia wywołań funkcji (rekurencyjnie) i w większości systemów rośnie od pamięci o wyższym adresie do pamięci o niższym adresie. Jeśli proces jest wielowątkowy, każdy wątek będzie miał unikalny stos. Jak zobaczysz, fakt, że stos rośnie od dużej pamięci do małej pamięci, pozwala na istnienie tematu przepełnienia bufora. Zmienne lokalne istnieją w sekcji stosu.