https://chacker.pl/
Teraz możemy zacząć pracę nad protokołem do komunikacji z narzędziami zewnętrznymi (od teraz będziemy je nazywać klientami). Zacznijmy od krótkiego omówienia wymagań protokołu:
- Jądro musi przetwarzać żądania od klienta, aby przechowywać i wykonywać dowolny kod.
- Jądro musi wysyłać odpowiedź z wynikami wykonania dowolnego kodu.
- Komunikacja jest inicjowana przez jądro. Musi ono poinformować klienta, że jest gotowe do przetwarzania żądań i powinno dostarczyć informacji
o swoim środowisku wykonawczym.
- Jądro może wysyłać wiadomości poza pasmem (OOB) w celu
debugowania.
- Integralność wiadomości musi zostać zweryfikowana.
Na podstawie tych wymagań będziemy oznaczać następujące typy wiadomości: żądanie, odpowiedź, wiadomości rozruchowe i wiadomości OOB. Wiadomości będą składać się z nagłówka o stałym rozmiarze i treści o zmiennym rozmiarze. Nagłówek będzie wskazywał typ wiadomości i długość treści oraz będzie zawierał sumy kontrolne integralności dla treści wiadomości i samego nagłówka:

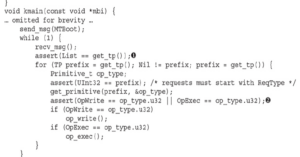
Wyliczenie MT (1) reprezentuje różne typy wiadomości, które można zakodować w polu typu nagłówka wiadomości. Pozostała część nagłówka zawiera długość (2), w bajtach, treści (mniej niż MAX_MSGSZ), sumę kontrolną zawartości treści (3) i sumę kontrolną treści nagłówka, z wyłączeniem zawartości samego pola hdr_csum (4). Format treści wiadomości musi być wystarczająco elastyczny, aby zakodować najczęstsze struktury danych, a jednocześnie procesy serializacji i deserializacji muszą być proste. Musi być łatwo generować dane z dowolnego kodu, a klient powinien również łatwo je konsumować i pracować z tymi danymi. Aby spełnić te potrzeby, zdefiniujemy kodowanie obejmujące wartości następujących typów: liczby całkowite, tablice, ciągi znaków i listy.

Każda wartość zaczyna się od 32-bitowego prefiksu zdefiniowanego w wyliczeniu TP (1). Prymitywy mogą być dowolnymi typami całkowitymi zdefiniowanymi w unii Primitive_t (2). Są one kodowane jako prefiks TP (mniejszy lub równy PrimitiveMax (3)), po którym następuje wartość w jego natywnym kodowaniu. Typy złożone mogą zawierać promienie, ciągi znaków i listy. Tablice zaczynają się od prefiksu Array (4), po którym następuje nagłówek Array_t:

Ten nagłówek wskazuje liczbę elementów i ich podtyp, który jest ograniczony do typów pierwotnych. Po nagłówku znajdują się wartości elementów w ich natywnym kodowaniu. Ciągi składają się z prefiksu CString (5), po którym następuje zmienna liczba bajtów innych niż null i są ograniczone sufiksem bajtu null. Listy zaczynają się od prefiksu List (6), po którym następuje zmienna liczba węzłów. Każdy węzeł jest parą, w której jego pierwszy element może być dowolną wartością z prefiksem TP (w tym inne listy), a jego drugi element jest następnym węzłem listy. Węzeł z prefiksem Nil (7) oznacza koniec listy. Mając już definicje wiadomości, możemy rozpocząć pracę nad jej wdrożeniem:

Najpierw potrzebujemy bufora (send_buf (1)) do skonstruowania treści wiadomości przed jej wysłaniem, a także bufora dla wiadomości przychodzących (2). Definiujemy również dodatkowy bufor (3) wyłącznie dla wiadomości OOB, więc jeśli wyślemy wiadomości debugowania w trakcie konstruowania wiadomości, nie usuniemy zawartości send_buf. Definiujemy kilka makr do kopiowania danych do i z buforów: GET kopiuje wartość z bufora odbiorczego, podczas gdy PUT kopiuje wartość do bufora docelowego wskazanego przez jego pierwszy parametr (przekażemy albo send_buf, albo oob_buf). Makro PUT wykonuje kilka dodatkowych kroków obejmujących podwójne użycie typeof w celu zdefiniowania zmiennej tmp (4). Należy zauważyć, że typeof akceptuje albo zmienną, albo wyrażenie na zewnętrznym typeof. Używamy tego drugiego: rzutowania zmiennej na jej własny typ. Powodem jest to, że wynikiem wyrażenia jest rvalue, więc jeśli oryginalna zmienna ma kwalifikator const, zostanie ona usunięta. W ten sposób przypisanie w (5) będzie sprawdzać typ, gdy przekażemy zmienną const do PUT. Teraz możemy zacząć pisać funkcje „put” i „get” dla każdej z wartości TP, które zdefiniowaliśmy:



UWAGA Funkcje „get” zostały pominięte w liście kodu ze względu na zwięzłość.
Pierwszy argument dla wszystkich funkcji „put” wskazuje, czy dane powinny zostać zapisane do send_buf czy do oob_buf. Dane są kodowane zgodnie ze schematem opisanym podczas definiowania różnych wartości TP. Dla wygody zaimplementowaliśmy również funkcję wariadyczną (1), która łączy wiele wartości różnych typów w jednym wywołaniu. Teraz potrzebujemy funkcji do wysyłania i odbierania wiadomości:

Funkcja send_msg (1) przyjmuje typ wiadomości jako argument, który jest najpierw używany do wybrania właściwego bufora do odczytania treści wiadomości. Oblicza sumy kontrolne treści i nagłówka (CRC32) i wysyła wiadomość przez port szeregowy. Na koniec resetuje przesunięcie bufora, aby można było utworzyć następną wiadomość. Aby pobrać wiadomość, recv_msg (2) odczytuje nagłówek wiadomości z portu szeregowego. Przed przejściem dalej wykonuje kontrole poprawności pól typu, długości i sumy kontrolnej nagłówka. Po przejściu tych kontroli odczytuje treść wiadomości i weryfikuje jej sumę kontrolną. Zakładamy, że klient nigdy nie wyśle nieprawidłowo sformatowanych wiadomości, więc jeśli kontrola poprawności się nie powiedzie, jest to konsekwencją uszkodzenia stanu jądra, co jest stanem nieodwracalnym i musimy ponownie uruchomić komputer.
UWAGA „Listy kodów dla funkcji crc32 i assert zostały pominięte ze względu na zwięzłość. Funkcja crc32 implementuje CRC32-C (wielomian 0x11EDC6F41), podczas gdy implementacja assert wysyła komunikat OOB i wykonuje twarde resety poprzez potrójne generowanie błędów.
Przetestujmy implementację protokołu, konstruując i wysyłając komunikat OOB:

Wyliczenie OOBType (1) definiuje dwa typy komunikatów OOB:
OOBPrint i OOBAssert. Treść komunikatu OOB to lista, gdzie pierwszym elementem jest OOBType. Makro OOB_PRINT (2) buduje tę listę na podstawie przekazanych mu argumentów, poprzedzając wartość OOBPrint i dodając prefiks CString do pierwszego argumentu odpowiadającego ciągowi formatującemu. Na koniec makro wysyła komunikat OOB przez port szeregowy. Należy zauważyć, że to makro nie może wywnioskować typów z ciągu formatującego, więc musimy przekazać wartości TP jako argumenty. Teraz możemy zastąpić nasz komunikat „Hello world” wywołaniem OOB_PRINT:

Przyjrzyjmy się danym wiadomości, przekierowując dane wyjściowe do hexdump (nie zapomnij uruchomić make, aby zbudować jądro w każdym laboratorium):
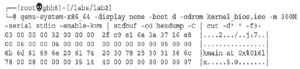
Oczywistym faktem, jaki możemy zobaczyć na tym wyjściu, jest to, że OOB_PRINT nie wykonuje formatowania ciągu. Nasze jądro nie wykona żadnej pracy, którą mógłby wykonać klient!