https://chacker.pl/
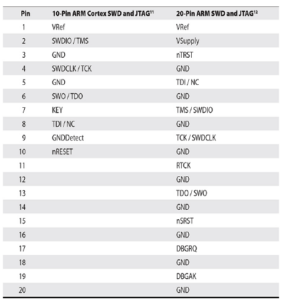
Joint Test Action Group (JTAG) została utworzona w latach 80. jako metoda ułatwiająca debugowanie i testowanie układów scalonych. W 1990 r. metoda została znormalizowana jako IEEE 1149.1, ale powszechnie nazywa się ją po prostu JTAG. Chociaż początkowo została stworzona, aby pomóc w testowaniu na poziomie płyty, jej możliwości umożliwiają debugowanie na poziomie sprzętu. Chociaż jest to zbytnie uproszczenie, JTAG definiuje mechanizm wykorzystywania kilku dostępnych zewnętrznie sygnałów w celu uzyskania dostępu do wnętrza układu scalonego za pośrednictwem znormalizowanej maszyny stanowej. Mechanizm jest znormalizowany, ale rzeczywista funkcjonalność za nim stojąca jest specyficzna dla układu scalonego. Oznacza to, że musisz znać debugowany układ scalony, aby skutecznie używać JTAG. Na przykład sekwencja bitów do procesora ARM i procesora MIPS będzie interpretowana inaczej przez wewnętrzną logikę procesora. Narzędzia takie jak OpenOCD wymagają plików konfiguracyjnych specyficznych dla urządzenia, aby działać prawidłowo. Mimo że producenci mogą definiować więcej pinów, opis czterech/pięciu pinów JTAG znajduje się w Tabeli.
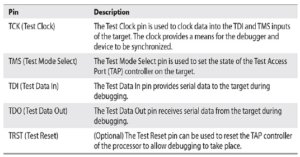
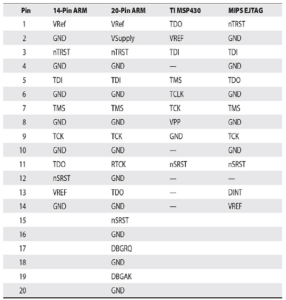
Zbiór pinów jest znany również jako port dostępu testowego (TAP). Chociaż można by pomyśleć, że pięć pinów ma standardowy układ, producenci płyt i układów scalonych definiują własne układy. Niektóre typowe układy pinów są zdefiniowane w Tabeli i obejmują konfiguracje 10-, 14- i 20-pinowe. Układy pinów w tabeli są tylko próbką i muszą zostać zweryfikowane przed użyciem z debugerem.
Dla programistów i testerów powszechnie używane są następujące możliwości:
- Zatrzymywanie procesora podczas debugowania
- Odczyt i zapis wewnętrznego magazynu programów (gdy kod jest przechowywany wewnątrz mikrokontrolera)
- Odczyt i zapis flash (modyfikacja lub ekstrakcja oprogramowania układowego)
- Odczyt i zapis pamięci
- Modyfikacja przepływu programu w celu pominięcia funkcjonalności w celu uzyskania ograniczonego dostępu
Jak widać, funkcjonalność dostępna dla interfejsu JTAG jest dość potężna. Producenci sprzętu znajdują się w tarapatach. Aby rozwijać, testować i debugować system wbudowany przez cały cykl jego życia, port JTAG jest niezbędny; jednak jego obecność na płycie daje badaczom i atakującym możliwość odkrywania sekretów, zmiany zachowania i znajdowania luk w zabezpieczeniach. Producenci zazwyczaj próbują utrudnić korzystanie z interfejsu JTAG po produkcji, przecinając linie, nie wypełniając pinów, nie oznaczając wyprowadzeń lub wykorzystując możliwości układu scalonego w celu jego wyłączenia. Chociaż jest to dość skuteczne, zdeterminowany atakujący ma wiele środków w swoim arsenale, aby ominąć zabezpieczenia, w tym naprawianie uszkodzonych ścieżek, lutowanie pinów na płytce, a nawet ewentualnie wysłanie układu scalonego do firmy specjalizującej się w wydobywaniu danych. Niektórzy mogą odrzucić JTAG jako słabość, ponieważ do jego użycia wymagany jest fizyczny, potencjalnie destrukcyjny dostęp. Problem z odrzuceniem ataku polega na tym, że atakujący może dowiedzieć się wiele o systemie za pomocą JTAG. Jeśli w systemie znajduje się globalny sekret, taki jak hasło, celowe tylne wejście do pomocy technicznej, klucz lub certyfikat, może on zostać wyodrębniony i następnie użyty do ataku na zdalny system.