Polecenie add dodaje źródło do miejsca docelowego i zapisuje wynik w miejscu docelowym. Polecenie sub odejmuje źródło od miejsca docelowego i zapisuje wynik w miejscu docelowym.

Polecenie add dodaje źródło do miejsca docelowego i zapisuje wynik w miejscu docelowym. Polecenie sub odejmuje źródło od miejsca docelowego i zapisuje wynik w miejscu docelowym.
Polecenie mov kopiuje dane ze źródła do miejsca docelowego. Wartość nie jest usuwana z lokalizacji źródłowej.

Chociaż na temat języka ASM napisano całe książki, możesz z łatwością opanować kilka podstaw, aby stać się bardziej skutecznym etycznym hakerem.
Maszyna kontra assembler kontra C
Komputery rozumieją tylko język maszynowy, czyli wzór składający się z jedynek i zer. Z drugiej strony ludzie mają problemy z interpretacją dużych ciągów jedynek i zer, dlatego asembler został zaprojektowany, aby pomóc programistom posługującym się mnemonikami w zapamiętaniu serii liczb. Później zaprojektowano języki wyższego poziomu, takie jak C i inne, które jeszcze bardziej oddalają ludzi od jedynek i zer. Jeśli chcesz zostać dobrym etycznym hakerem, musisz oprzeć się trendom społecznym i wrócić do podstaw w zakresie assemblera.
Rejestry służą do tymczasowego przechowywania danych. Pomyśl o nich jak o szybkich fragmentach pamięci o długości od 8 do 64 bitów, które będą wykorzystywane wewnętrznie przez procesor. Rejestry można podzielić na cztery kategorie (rejestry 32-bitowe są poprzedzone literą E, a rejestry 64-bitowe są poprzedzone literą R, tak jak w EAX i RAX). Są one wymienione i opisane w Tabeli .
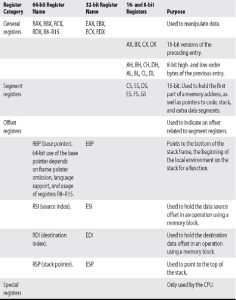

Istnieje kilka powszechnie używanych architektur komputerów. W tym rozdziale skupimy się na rodzinie procesorów lub architekturze Intel. Termin architektura odnosi się po prostu do sposobu, w jaki konkretny producent zaimplementował swój procesor. Architektury x86 (32-bitowe) i x86-64 (64-bitowe) są nadal najczęściej używane, a inne architektury, takie jak ARM, rozwijają się każdego roku. Każda architektura wykorzystuje unikalny zestaw instrukcji. Instrukcje z jednej architektury procesora nie są rozumiane przez inny procesor.
Teraz, gdy znasz już podstawy, przyjrzymy się prostemu przykładowi ilustrującemu użycie pamięci w programie.
memory.c
Najpierw wylistujemy zawartość programu za pomocą cat:

Ten program niewiele robi. Po pierwsze, kilka fragmentów pamięci jest alokowanych w różnych sekcjach pamięci procesu. Kiedy wykonywana jest funkcja main (1), wywoływana jest funkcja funct1() z argumentem 1 (2) . Po wywołaniu funkcji funct1() argument jest przekazywany do zmiennej funkcji o nazwie c (3) . Następnie przydzielana jest pamięć na stercie dla 10-bajtowego ciągu zwanego str (4). Na koniec 5-bajtowy ciąg „abcde” jest kopiowany do nowej zmiennej o nazwie str (5) . Funkcja kończy się, a następnie program main() (6).
Wskaźniki to specjalne fragmenty pamięci przechowujące adresy innych fragmentów pamięci. Przenoszenie danych wewnątrz pamięci jest operacją stosunkowo powolną. Okazuje się, że zamiast przenosić dane, znacznie łatwiej jest śledzić lokalizację elementów w pamięci za pomocą wskaźników i po prostu zmieniać wskaźniki. Wskaźniki są zapisywane w 4 lub 8 bajtach ciągłej pamięci, w zależności od tego, czy aplikacja jest 32-bitowa, czy 64-bitowa. Na przykład, jak wspomniano, do łańcuchów odwołuje się adres pierwszego znaku w tablicy. Ta wartość adresu nazywana jest wskaźnikiem. Deklarację zmiennej ciągu w C zapisuje się w następujący sposób:
![]()
Zauważ, że chociaż rozmiar wskaźnika jest ustawiony na 4 lub 8 bajtów, w zależności od architektury, rozmiar łańcucha nie został ustawiony za pomocą poprzedniego polecenia; dlatego dane te są uważane za niezainicjowane i zostaną umieszczone w sekcji .bss pamięci procesu. Oto kolejny przykład; jeśli chcesz zapisać w pamięci wskaźnik do liczby całkowitej, wydasz w programie C następujące polecenie:
![]()
Aby odczytać wartość adresu pamięci wskazywanego przez wskaźnik, należy wyrejestrować wskaźnik za pomocą symbolu *. Dlatego jeśli chcesz wydrukować wartość liczby całkowitej wskazywanej przez punkt 1 w poprzednim kodzie, użyj polecenia
printf(„%d”, *point1);
gdzie * służy do usuwania referencji wskaźnika zwanego punktem 1 i wyświetlania wartości liczby całkowitej za pomocą funkcji printf().
Mówiąc najprościej, ciągi znaków to po prostu ciągłe tablice danych znakowych w pamięci. Do łańcucha odwołuje się w pamięci adres pierwszego znaku. Łańcuch jest zakończony lub zakończony znakiem null (\0 w C). \0 jest przykładem sekwencji ucieczki. Sekwencje ucieczki umożliwiają programiście określenie specjalnej operacji, takiej jak znak nowej linii z \n lub powrót karetki z \r. Ukośnik odwrotny zapewnia, że kolejny znak nie będzie traktowany jako część ciągu. Jeśli potrzebny jest ukośnik odwrotny, można po prostu użyć sekwencji ucieczki \\, która wyświetli tylko pojedynczy \. Tabele różnych sekwencji ucieczki można znaleźć w Internecie.
Termin bufor odnosi się do miejsca przechowywania używanego do odbierania i przechowywania danych do czasu, aż będą mogły zostać obsłużone przez proces. Ponieważ każdy proces może mieć swój własny zestaw buforów, niezwykle ważne jest, aby były one proste; odbywa się to poprzez alokację pamięci w sekcji .data lub .bss pamięci procesu. Pamiętaj, że raz przydzielony bufor ma stałą długość. Bufor może przechowywać dowolny, predefiniowany typ danych; jednak dla naszych celów skupimy się na buforach opartych na ciągach znaków, które służą do przechowywania danych wejściowych użytkownika i zmiennych tekstowych.
Sekcja środowisko/argumenty służy do przechowywania kopii zmiennych na poziomie systemu, które mogą być wymagane przez proces w czasie wykonywania. Na przykład uruchomionemu procesowi udostępniana jest między innymi ścieżka, nazwa powłoki i nazwa hosta. Ta sekcja jest zapisywalna, co pozwala na jej wykorzystanie w exploitach związanych z przepełnieniem ciągu formatującego i bufora. Dodatkowo w tym obszarze przechowywane są argumenty wiersza poleceń. Sekcje pamięci znajdują się w przedstawionej kolejności. Przestrzeń pamięci procesu wygląda następująco:
