https://chacker.pl/
Systemy C2 często umożliwiają szablony komunikacji. Ponieważ HTTP jest najpopularniejszym protokołem komunikacji C2, ważne jest, aby podczas tworzenia szablonów komunikacji wiedzieć, gdzie najlepiej umieścić dane. Szablony określają lokalizacje, w których dane będą umieszczane podczas wysyłania i odbierania danych za pomocą systemu C2. Na przykład wiele systemów C2 umożliwia uruchomienie żądania GET dotyczącego meldowania się i pobierania poleceń, a także żądania POST w celu odesłania danych z powrotem. Przykładowe żądanie GET może wyglądać następująco:

Widzimy tutaj, że identyfikator serwera C2 może być zawarty w linii URI. Byłoby to łatwe do zobaczenia i dopasowania różnych zaangażowanych gospodarzy. Chociaż ta prosta formuła jest powszechna, lepiej byłoby umieścić wartości w pliku cookie. Pliki cookie nie są rejestrowane na wszystkich serwerach proxy i nie są pierwszą rzeczą, na którą ludzie patrzą w raportach, dlatego też wymagają dodatkowego kopania, aby je zobaczyć. Do wysyłania danych wiele osób korzysta z żądań POST, ponieważ dane znajdują się w ładunku. Sposób przedstawienia tych danych może wymagać przemyślenia. Bardzo prosty profil może wyglądać następująco:
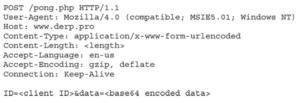
Chociaż jest to podstawowa kwestia, większość krytycznych danych znajduje się w treści żądania POST, co oznacza, że prawdopodobnie nie zostaną one nigdzie zarejestrowane. Ponieważ to jest zakodowane w standardzie base64, można go łatwo zdekodować za pomocą automatycznych narzędzi. Wybór lepszego schematu kodowania i szyfrowanie danych może utrudnić dekodowanie. Ponadto dopasowanie klienta użytkownika do domyślnej przeglądarki użytkownika, a następnie użycie podobnych nagłówków sprawi, że będzie wyglądać bardziej normalnie. Ponieważ ten szablon jest tak prosty, oczywiste jest, że jest to ruch C2. Jeśli jednak sprawisz, że żądania GET i POST będą wyglądać tak, jakby korzystały z interfejsu API REST lub innego rodzaju rzeczywistego ruchu HTTP, oprócz wybrania lepszych nagłówków i klienta użytkownika, możesz jeszcze lepiej to połączyć. Ogólnie rzecz biorąc, wybranie realistycznie wyglądającego profilu, a następnie użycie tych samych nagłówków, których używa zwykły użytkownik systemu, zwiększy szansę na uniknięcie wykrycia.