https://chacker.pl/
W tym laboratorium postaramy się udowodnić hipotezę, że ktoś inny niż administrator uruchomił PowerShell. Pamiętaj, że może to być złośliwe lub nie, ale jest to dobry punkt wyjścia. W zależności od rozmiaru sieci możesz używać dużo programu PowerShell, ale powinieneś być w stanie odizolować użytkowników administratorów, a następnie wykryć innych użytkowników programu PowerShell. Nawiasem mówiąc, jest to dobry pierwszy krok, ale ostatecznie będziesz chciał monitorować i badać także wszystkie swoje działania administracyjne. W końcu, jeśli jedno z nich zostanie naruszone, osoba atakująca chciałaby wykorzystać swoje uprawnienia w sieci. Aby zapoznać się ze wszystkimi sposobami uruchomienia programu PowerShell, wracamy do naszego notatnika OSSEM Jupyter z laboratorium 9-1. Jeśli upłynął limit czasu, może być konieczne ponowne uruchomienie — w końcu jest darmowy! Sprawdzając framework MITRE ATT&CK, widzimy, że T1059.001 to technika lokalnego uruchamiania PowerShell:

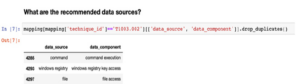
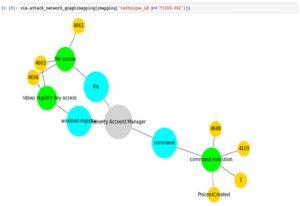
Spójrzmy na diagram OSSEM tej techniki, jak pokazano poniżej. Wyrób sobie w tym nawyk.
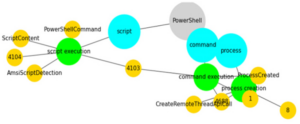
Widzimy tutaj kilka ścieżek wykrywania wykonania programu PowerShell za pośrednictwem skryptów, wiersza poleceń i tworzenia procesów. Ponieważ w poprzednim rozdziale załadowaliśmy dane Mordoru, utwórzmy indeks. Kliknij ikonę K w lewym górnym rogu portalu Kibana, aby przejść do strony głównej; następnie przewiń w dół i kliknij opcję Wzorce indeksowania w obszarze Zarządzaj i administruj stosem elastycznym:
Następnie kliknij niebieski przycisk Utwórz wzór indeksu u góry ekranu:

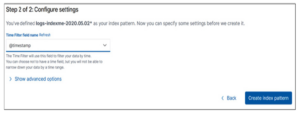
Wpisz logs-indexme-2020.05.02* w polu Wzorzec indeksu, a następnie kliknij przycisk Następny krok:

W polu Nazwa pola filtru czasu wybierz @timestamp i kliknij przycisk Utwórz wzorzec indeksu:
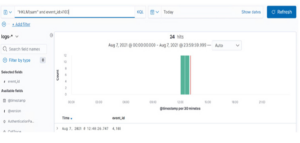
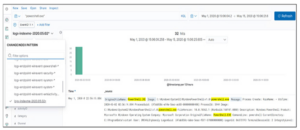
Po utworzeniu indeksu możesz go wybrać po lewej stronie Panel Kibany. Następnie wyszukaj „powershell.exe” z filtrem EventID: 1 i zakresem dat, jak pokazano poniżej:
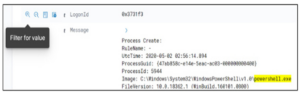
Teraz, gdy mamy już wszystkie dzienniki programu PowerShell.exe w naszym środowisku, możemy filtrować pod kątem określonej wartości pola indeksowanego; na przykład moglibyśmy otworzyć (rozwinąć) dziennik i przewinąć w dół do LogonID (0x3731f3). LogonID pozostaje stały przez całą sesję użytkownika i jest przydatny do śledzenia jego innych działań. Zatem najedźmy kursorem na lupę (ze znakiem plus), jak pokazano poniżej, a następnie wybierz opcję Filtruj według wartości.
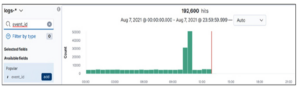
Spowoduje to dodanie filtra dla LogonId: 0x3731f3, pokazując nam resztę logów. Następnie wyszukaj „cmd.exe”, jak pokazano poniżej, aby wyszukać aktywność wiersza poleceń:

Widzimy siedem trafień. Przewijając logi w dół, widzimy wskazówkę: pole ParentImage (plik, który został użyty do utworzenia bieżącego procesu) ma dziwną nazwę. Wygląda jak plik wygaszacza ekranu.
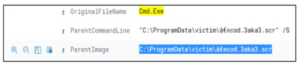
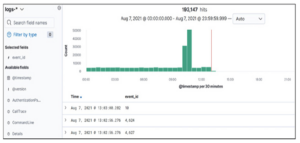
Teraz, szukając tej nazwy pliku, widzimy, że mamy pięć trafień. Przewijając te logi, widzimy naszego użytkownika: DMEVALS\pbeesly.
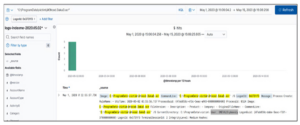
Teraz znamy tę użytkownika i nie jest ona administratorem. Nie powinna używać programu PowerShell, więc szukajmy dalej. Dodając jej nazwę użytkownika do zapytania w następujący sposób, w logach znajdujemy połączenia sieciowe:
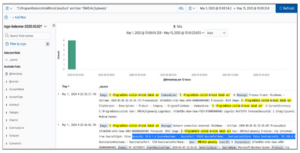
Czego się nauczyliśmy? Dzięki inżynierii wstecznej dotychczasowego ataku dowiedzieliśmy się, że osoba atakująca wykonała następujące czynności:
- Użytkownik DMEVALS\pbeees został wykonany
„C:\ProgramData\victim\‮cod.3aka3.scr”.
- Ten plik otworzył połączenie sieciowe.
- Następnie ten plik otworzył cmd.exe.
- Cmd.exe otworzył PowerShell.
Jak widzieliście, zaczęliśmy od hipotezy, ale w trakcie tego procesu znaleźliśmy się w środku frameworka MITRE ATT&CK, w fazie wykonania. Następnie pracowaliśmy wstecz, aby znaleźć źródło działania oraz użytkownika i maszynę. Teraz prawdopodobnie nadszedł czas, aby skontaktować się z zespołem reagowania na incydenty i współpracować z nim w celu ustalenia zasięgu ataku, ponieważ na tym etapie mamy dopiero początek — przynajmniej do następnego laboratorium!