Istnieje kilka powodów, dla których Spark i Jupyter są potrzebne do usprawnienia naszej nauki. Chociaż Elasticsearch jest dobry, nie jest relacyjną bazą danych, więc okazuje się, że łączenia są kosztowne obliczeniowo. Łączenie to funkcja wspólna dla SQL, która pozwala nam łączyć dane w ramach zapytania, aby być bardziej przedmiotem naszych dochodzeń. Na przykład, gdybyśmy mieli dwa źródła danych, jedno z static_ip i nazwą_użytkownika, a drugie ze static_ip i nazwą_hosta, moglibyśmy je połączyć w następujący sposób. Lewe połączenie zwraca rekordy z lewego źródła z dopasowaniami z prawego źródła:
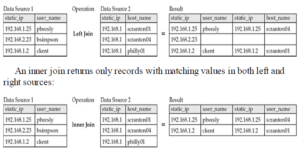
Pełne złączenie zewnętrzne zwraca rekordy, jeśli istnieje dopasowanie z któregokolwiek źródła:
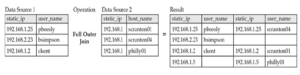
Złączenia te można wykonać za pomocą Apache Spark, wykorzystując dane z Elasticsearch, co jest szczególnie przydatne podczas polowania na zagrożenia, umożliwiając nam ulepszanie lub wzbogacanie naszych danych poprzez połączenie kilku źródeł danych. Zobaczymy, jak to się rozegra w następnym laboratorium.