https://chacker.pl/
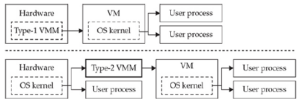
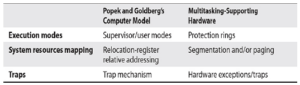
Wiemy, że architektura wirtualizowalna wymaga dwóch trybów działania: trybu nadzorcy do uruchamiania VMM i trybu użytkownika do uruchamiania programów VM. Gdy x86 przejdzie w tryb chroniony, zapewnione są cztery poziomy ochrony (pierścienia), z których dwa są powszechnie używane przez systemy operacyjne: Ring-0 dla kodu jądra i Ring-3 dla programów użytkownika. Próby wykonania instrukcji uprzywilejowanej na dowolnym poziomie pierścienia innym niż Ring-0 powodują pułapkę (#GPF). Zgodnie z tym projektem maszyny wirtualne powinny być wykonywane tylko na poziomach pierścienia 1–3, podczas gdy VMM powinien działać na poziomie Ring-0. Aby to osiągnąć, jądro systemu operacyjnego działające na maszynie wirtualnej musi zostać zdegradowane z poziomu Ring-0 do jednego z pozostałych poziomów. Mechanizm stronicowania x86 może rozróżniać tylko strony „supervisor” i „user”. Poziomy pierścienia 0–2 mogą uzyskać dostęp do obu (z wyjątkiem sytuacji, gdy wymuszane są SMAP i SMEP15), podczas gdy Ring-3 może uzyskać dostęp tylko do stron „user”. Tak więc, jeśli chcemy użyć stronicowania do ochrony pamięci VMM, maszyny wirtualne powinny mieć możliwość działania tylko w trybie Ring-3. Oznacza to, że nie byłoby różnicy w poziomie uprawnień jądra i jego procesów użytkownika. W typowej implementacji systemu operacyjnego wirtualna przestrzeń adresowa jest podzielona na dwie połowy, mapując pamięć jądra na każdy proces użytkownika. Ten schemat ma kilka zalet, takich jak proste rozróżnianie wskaźników użytkownika/jądra, przechowywanie adresów jądra w pamięci podręcznej w TLB i możliwość wykonywania bezpośrednich operacji kopiowania z jądra na adresy użytkownika. Z drugiej strony, takie współdzielenie przestrzeni adresowej ułatwiało eksploatację jądra przez długi czas i stworzyło potrzebę wielu środków zaradczych (KASLR,16 UDEREF,17 SMEP i SMAP).
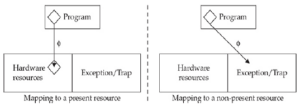
UWAGA W ostatnich latach odkryto szereg luk w zabezpieczeniach związanych z wykonywaniem przejściowym, które mogą być wykorzystane między innymi do wycieku zawartości pamięci uprzywilejowanej do trybu użytkownika. Aby złagodzić wiele z nich, wymuszana jest izolacja tabeli stron jądra (KPTI19); co zabawne, działa ona poprzez usuwanie większości mapowań jądra z procesów użytkownika, co niweczy większość korzyści wydajnościowych zapewnianych przez podział pamięci.
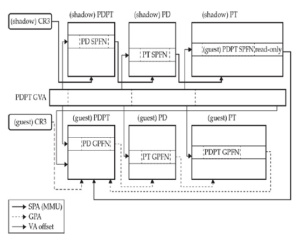
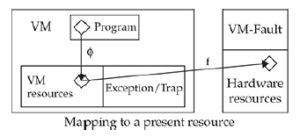
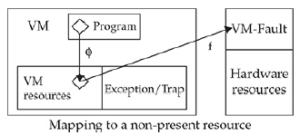
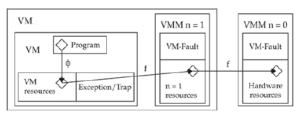
Współdzielenie przestrzeni adresowej staje się problematyczne, gdy jądro zostanie umieszczone w Ring-3. Tak jak jest, VMM nie może chronić pamięci jądra dla procesów użytkownika, chyba że zostanie ona odmapowana i ponownie zamapowana między przełączeniami kontekstowymi, ale byłoby to zbyt kosztowne. Rozwiązaniem jest umieszczenie jądra w Ring-1. W ten sposób stronicowanie może chronić pamięć jądra (strony nadzorcy) przed przestrzenią użytkownika. Jest pewien haczyk: stronicowanie nie może chronić stron nadzorcy VMM przed Ring-1, jednak nadal możemy użyć segmentacji, aby chronić pamięć VMM przed jądrem gościa.
UWAGA: x86_64 usunął większość funkcji segmentacji, więc rozwiązanie Ring-1 nie może być używane w trybie długim. Niektóre modele częściowo obsługują limity segmentów za pośrednictwem funkcji EFER.LMSLE20, ale obecnie częściej spotyka się procesory x86_64 z rozszerzeniami wirtualizacji sprzętowej, co, jak zobaczymy później, oszczędzi nam kłopotu związanego z martwieniem się o kompresję pierścieniową.
UWAGA: x86_64 usunął większość funkcji segmentacji, więc rozwiązanie Ring-1 nie może być używane w trybie długim. Niektóre modele częściowo obsługują limity segmentów za pośrednictwem funkcji EFER.LMSLE20, ale obecnie częściej spotyka się procesory x86_64 z rozszerzeniami wirtualizacji sprzętowej, co, jak zobaczymy później, oszczędzi nam kłopotu związanego z martwieniem się o kompresję pierścieniową.