Koncepcję stosu w informatyce można najlepiej wyjaśnić, porównując ją do stosu tacek z lunchem w szkolnej stołówce. Gdy kładziesz tacę na stosie, taca, która wcześniej była na górze, jest teraz przykryta. Gdy bierzesz tacę ze stosu, bierzesz tacę z góry stosu, który jest ostatnią tam położoną. Bardziej formalnie, w terminologii informatycznej, stos jest strukturą danych, która ma jakość kolejki FILO (first in, last out). Proces umieszczania elementów na stosie nazywa się push i jest wykonywany w kodzie języka asemblera za pomocą polecenia push. Podobnie proces pobierania elementu ze stosu nazywa się pop i jest wykonywany za pomocą polecenia pop w kodzie języka asemblera.
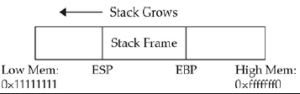
Każdy uruchomiony program ma swój własny stos w pamięci. Stos rośnie wstecz od najwyższego adresu pamięci do najniższego. Oznacza to, że używając naszego przykładu tacy kawiarnianej, dolna taca byłaby najwyższym adresem pamięci, a górna taca najniższa. Dwa ważne rejestry zajmują się stosem: Extended Base Pointer (EBP) i Extended Stack Pointer (ESP). Jak pokazano na rysunku, rejestr EBP jest podstawą bieżącej ramki stosu procesu (wyższy adres). Rejestr ESP zawsze wskazuje na szczyt stosu (niższy adres). Jak wyjaśniono w rozdziale 2, funkcja jest samodzielnym modułem kodu, który może być wywoływany przez inne funkcje, w tym funkcję main(). Gdy funkcja jest wywoływana, powoduje to skok w przepływie programu. Gdy funkcja jest wywoływana w kodzie asemblera, dzieją się trzy rzeczy:
- Zgodnie z konwencją, wywołujący program konfiguruje wywołanie funkcji, najpierw umieszczając parametry funkcji na stosie w odwrotnej kolejności.
- Następnie wskaźnik Extended Instruction Pointer (EIP) jest zapisywany na stosie, aby program mógł kontynuować od miejsca, w którym został przerwany, gdy funkcja zwróci wartość. Jest to określane jako adres powrotu.
- Na koniec wykonywane jest polecenie wywołania, a adres funkcji umieszczany jest w EIP w celu wykonania
W kodzie języka asemblera wywołanie wygląda następująco:

Obowiązki wywoływanej funkcji to najpierw zapisanie rejestru EBP wywołującego programu na stosie, następnie zapisanie bieżącego rejestru ESP do rejestru EBP (ustawienie bieżącej ramki stosu), a następnie zmniejszenie rejestru ESP, aby zrobić miejsce dla zmiennych lokalnych funkcji. Na koniec funkcja otrzymuje możliwość wykonania swoich instrukcji. Ten proces nazywa się prologiem funkcji. W kodzie asemblera prolog wygląda tak:

Ostatnią rzeczą, jaką robi wywoływana funkcja przed powrotem do wywołującego programu, jest wyczyszczenie stosu poprzez zwiększenie ESP do EBP, co skutecznie czyści stos jako część instrukcji leave. Następnie zapisany EIP jest usuwany ze stosu jako część procesu powrotu. Jest to określane jako epilog funkcji. Jeśli wszystko pójdzie dobrze, EIP nadal przechowuje następną instrukcję do pobrania, a proces jest kontynuowany za pomocą instrukcji po wywołaniu funkcji. W kodzie asemblera epilog wygląda następująco:
![]()
Te małe fragmenty kodu języka asemblera będziesz wielokrotnie spotykać podczas poszukiwania przepełnień bufora.