Aby zbudować skuteczny exploit w sytuacji przepełnienia bufora, musisz utworzyć większy bufor niż program oczekuje, używając następujących składników: NOP sled, shellcode i adresu powrotu.
Aby zbudować skuteczny exploit w sytuacji przepełnienia bufora, musisz utworzyć większy bufor niż program oczekuje, używając następujących składników: NOP sled, shellcode i adresu powrotu.
Jednym z głównych celów wykorzystywania lokalnego przepełnienia bufora jest kontrolowanie EIP w celu uzyskania wykonania dowolnego kodu w celu osiągnięcia eskalacji uprawnień. W tej sekcji omówimy niektóre z najczęstszych luk w zabezpieczeniach i sposoby ich wykorzystania
Program meet.c wgląda następująco:

Użyjemy Pythona, aby przepełnić bufor 400-bajtowy w meet.c. Python jest językiem interpretowanym, co oznacza, że nie trzeba go prekompilować, co czyni go bardzo wygodnym w użyciu w wierszu poleceń. Na razie musisz zrozumieć tylko jedno polecenie Pythona:
![]()
To polecenie po prostu wydrukuje 600 A na standardowym wyjściu (stdout) — spróbuj!
UWAGA Znaki odwrotnego apostrofu (`) są używane do opakowania polecenia i wykonania polecenia przez interpreter powłoki oraz zwrócenia wartości. Skompilujmy i wykonajmy meet.c:

Teraz przekażmy 600 A do programu meet.c jako drugi parametr w następujący sposób:
![]()
Zgodnie z oczekiwaniami, Twój 400-bajtowy bufor przepełnił się; miejmy nadzieję, że EIP również. Aby to sprawdzić, uruchom ponownie gdb:

UWAGA: Twoje wartości mogą być inne. Pamiętaj, że próbujemy tu przekazać koncepcję, a nie wartości pamięci.
Nie tylko nie kontrolowaliśmy EIP, ale przenieśliśmy się daleko do innej części pamięci. Jeśli spojrzysz na meet.c, zauważysz, że po funkcji strcpy() w funkcji powitania następuje wywołanie printf(), które z kolei wywołuje vfprintf() w bibliotece libc. Funkcja vfprintf() wywołuje następnie strlen. Ale co mogło pójść nie tak? Masz kilka zagnieżdżonych funkcji, a zatem kilka ramek stosu, z których każda została umieszczona na stosie. Kiedy spowodowałeś przepełnienie, musiałeś uszkodzić argumenty przekazane do funkcji printf(). Przypomnij sobie z poprzedniej sekcji, że wywołanie i prolog funkcji sprawiają, że stos wygląda jak na poniższej ilustracji:
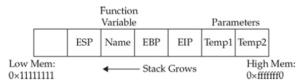
Jeśli zapiszesz poza EIP, nadpiszesz argumenty funkcji, zaczynając od temp1. Ponieważ funkcja printf() używa temp1, będziesz miał problemy. Aby sprawdzić tę teorię, sprawdźmy ponownie w gdb. Kiedy uruchomimy gdb ponownie, możemy spróbować uzyskać listę źródłową:

W poprzednim pogrubionym wierszu widać, że argumenty funkcji temp1 i temp2 zostały uszkodzone. Wskaźniki wskazują teraz na 0x41414141, a wartości to „” (lub null). Problem polega na tym, że printf() nie przyjmuje wartości null jako jedynego wejścia i dlatego się dławi. Zacznijmy więc od mniejszej liczby A, takiej jak 405, a następnie powoli ją zwiększajmy, aż uzyskamy pożądany efekt:
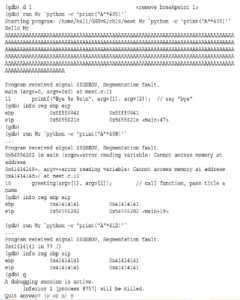
Jak widać, gdy w gdb występuje błąd segmentacji, wyświetlana jest bieżąca wartość EIP. Ważne jest, aby zdać sobie sprawę, że liczby (400–412) nie są tak ważne jak koncepcja zaczynania od niskiego poziomu i powolnego zwiększania, aż do przepełnienia zapisanego EIP i niczego więcej. Dzieje się tak z powodu wywołania printf bezpośrednio po przepełnieniu. Czasami będziesz mieć więcej miejsca na oddech i nie będziesz musiał się tym zbytnio martwić. Na przykład, gdyby nic nie następowało po podatnym poleceniu strcpy, nie byłoby problemu z przepełnieniem powyżej 412 bajtów w tym przypadku.
UWAGA: Pamiętaj, że używamy tutaj bardzo prostego fragmentu wadliwego kodu; w prawdziwym życiu napotkasz wiele takich problemów. Ponownie, chcemy, abyś zrozumiał koncepcje, a nie liczby wymagane do przepełnienia konkretnego podatnego fragmentu kodu.
eraz, gdy znasz już podstawy, możemy przejść do konkretów. Jak opisano w rozdziale 2, bufory służą do przechowywania danych w pamięci. Nas interesują głównie bufory przechowujące ciągi znaków. Same bufory nie mają mechanizmów ograniczających, które uniemożliwiałyby dodawanie większej ilości danych niż oczekiwano. W rzeczywistości, jeśli jako programista będziesz niedbały, możesz szybko
przekroczyć przydzieloną przestrzeń. Na przykład poniższy kod deklaruje ciąg znaków w pamięci o rozmiarze 10 bajtów:
![]()
Co się stanie jeśli wykonasz poniższe polecenie?
![]()
Teraz musimy skompilować i wykonać program 32-bitowy. Ponieważ mamy 64-bitowy Kali Linux, najpierw musimy zainstalować gcc-multilib, aby dokonać cross-kompilacji 32-bitowych plików binarnych:
![]()
Po zainstalowaniu gcc-multilib następnym krokiem jest kompilacja naszego programu przy użyciu opcji -m32 i -fno-stack-protector w celu wyłączenia ochrony Stack Canary:
![]()
UWAGA: W systemach operacyjnych w stylu Linuxa warto zwrócić uwagę na konwencję dotyczącą monitów, która pomaga odróżnić powłokę użytkownika od powłoki roota. Zazwyczaj powłoka roota będzie miała znak # jako część monitu, podczas gdy powłoki użytkownika zazwyczaj mają znak $ w monicie. Jest to wizualna wskazówka, która pokazuje, gdy udało Ci się eskalować swoje uprawnienia, ale nadal będziesz chciał to zweryfikować za pomocą polecenia, takiego jak whoami lub id. Dlaczego otrzymałeś błąd segmentacji? Zobaczmy, uruchamiając gdb (GNU Debugger):
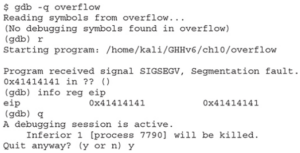
UWAGA Randomizacja układu przestrzeni adresowej (ASLR) działa poprzez losowe ustalanie lokalizacji różnych sekcji programu w pamięci, w tym bazy wykonywalnej, stosu, sterty i bibliotek, co utrudnia atakującemu niezawodne przejście do określonego adresu pamięci. Aby wyłączyć ASLR, uruchom następujące polecenie w wierszu poleceń:$ echo 0 | sudo tee /proc/sys/kernel/randomize_va_space Teraz przyjrzyjmy się atakowi na meet.c.
Koncepcję stosu w informatyce można najlepiej wyjaśnić, porównując ją do stosu tacek z lunchem w szkolnej stołówce. Gdy kładziesz tacę na stosie, taca, która wcześniej była na górze, jest teraz przykryta. Gdy bierzesz tacę ze stosu, bierzesz tacę z góry stosu, który jest ostatnią tam położoną. Bardziej formalnie, w terminologii informatycznej, stos jest strukturą danych, która ma jakość kolejki FILO (first in, last out). Proces umieszczania elementów na stosie nazywa się push i jest wykonywany w kodzie języka asemblera za pomocą polecenia push. Podobnie proces pobierania elementu ze stosu nazywa się pop i jest wykonywany za pomocą polecenia pop w kodzie języka asemblera.
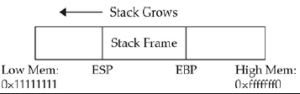
Każdy uruchomiony program ma swój własny stos w pamięci. Stos rośnie wstecz od najwyższego adresu pamięci do najniższego. Oznacza to, że używając naszego przykładu tacy kawiarnianej, dolna taca byłaby najwyższym adresem pamięci, a górna taca najniższa. Dwa ważne rejestry zajmują się stosem: Extended Base Pointer (EBP) i Extended Stack Pointer (ESP). Jak pokazano na rysunku, rejestr EBP jest podstawą bieżącej ramki stosu procesu (wyższy adres). Rejestr ESP zawsze wskazuje na szczyt stosu (niższy adres). Jak wyjaśniono w rozdziale 2, funkcja jest samodzielnym modułem kodu, który może być wywoływany przez inne funkcje, w tym funkcję main(). Gdy funkcja jest wywoływana, powoduje to skok w przepływie programu. Gdy funkcja jest wywoływana w kodzie asemblera, dzieją się trzy rzeczy:
W kodzie języka asemblera wywołanie wygląda następująco:

Obowiązki wywoływanej funkcji to najpierw zapisanie rejestru EBP wywołującego programu na stosie, następnie zapisanie bieżącego rejestru ESP do rejestru EBP (ustawienie bieżącej ramki stosu), a następnie zmniejszenie rejestru ESP, aby zrobić miejsce dla zmiennych lokalnych funkcji. Na koniec funkcja otrzymuje możliwość wykonania swoich instrukcji. Ten proces nazywa się prologiem funkcji. W kodzie asemblera prolog wygląda tak:

Ostatnią rzeczą, jaką robi wywoływana funkcja przed powrotem do wywołującego programu, jest wyczyszczenie stosu poprzez zwiększenie ESP do EBP, co skutecznie czyści stos jako część instrukcji leave. Następnie zapisany EIP jest usuwany ze stosu jako część procesu powrotu. Jest to określane jako epilog funkcji. Jeśli wszystko pójdzie dobrze, EIP nadal przechowuje następną instrukcję do pobrania, a proces jest kontynuowany za pomocą instrukcji po wywołaniu funkcji. W kodzie asemblera epilog wygląda następująco:
![]()
Te małe fragmenty kodu języka asemblera będziesz wielokrotnie spotykać podczas poszukiwania przepełnień bufora.
Dlaczego badać exploity? Etyczni hakerzy powinni badać exploity, aby zrozumieć, czy luki w zabezpieczeniach są podatne na wykorzystanie. Czasami specjaliści ds. bezpieczeństwa błędnie wierzą i publicznie stwierdzają, że dana luka w zabezpieczeniach nie jest możliwa do wykorzystania, ale hakerzy black hat wiedzą co innego. Niezdolność jednej osoby do znalezienia exploita dla luki w zabezpieczeniach nie oznacza, że ktoś inny nie może tego zrobić. To kwestia czasu i poziomu umiejętności. Dlatego etyczni hakerzy muszą zrozumieć, jak wykorzystywać luki w zabezpieczeniach i sprawdzić to sami. W tym procesie mogą musieć stworzyć kod proof-of-concept, aby wykazać dostawcy, że luka w zabezpieczeniach jest możliwa do wykorzystania i należy ją naprawić. W tym rozdziale skupimy się na wykorzystywaniu 32-bitowych przepełnień stosu Linuksa, wyłączaniu technik łagodzenia exploitów w czasie kompilacji i losowym rozmieszczeniu przestrzeni adresowej (ASLR). Postanowiliśmy zacząć od tych tematów, ponieważ są łatwiejsze do zrozumienia.Dlaczego badać exploity? Etyczni hakerzy powinni badać exploity, aby zrozumieć, czy luki w zabezpieczeniach są podatne na wykorzystanie. Czasami specjaliści ds. bezpieczeństwa błędnie wierzą i publicznie stwierdzają, że dana luka w zabezpieczeniach nie jest możliwa do wykorzystania, ale hakerzy black hat wiedzą co innego. Niezdolność jednej osoby do znalezienia exploita dla luki w zabezpieczeniach nie oznacza, że ktoś inny nie może tego zrobić. To kwestia czasu i poziomu umiejętności. Dlatego etyczni hakerzy muszą zrozumieć, jak wykorzystywać luki w zabezpieczeniach i sprawdzić to sami. W tym procesie mogą musieć stworzyć kod proof-of-concept, aby wykazać dostawcy, że luka w zabezpieczeniach jest możliwa do wykorzystania i należy ją naprawić. W tym rozdziale skupimy się na wykorzystywaniu 32-bitowych przepełnień stosu Linuksa, wyłączaniu technik łagodzenia exploitów w czasie kompilacji i losowym rozmieszczeniu przestrzeni adresowej (ASLR). Postanowiliśmy zacząć od tych tematów, ponieważ są łatwiejsze do zrozumienia.
Zajęliśmy się tematem polowania na zagrożenia. Jak stwierdzono na początku rozdziału, Twoje umiejętności polowania na zagrożenia będą musiały być rozwijane przez lata praktyki, a ten rozdział pomógł w ustaleniu podstaw. Zaczęliśmy od omówienia źródeł danych i sposobu normalizacji danych za pomocą OSSEM. Następnie przeszliśmy do podstawowych procesów polowania na zagrożenia, w tym polowań opartych na danych i hipotezach. Przeszliśmy przez serię laboratoriów, których celem było poznanie wymaganych umiejętności i zapewnienie podstaw do poszerzenia wiedzy. Na koniec pokazaliśmy, jak rozszerzyć te umiejętności w prawdziwej sieci operacyjnej, poza laboratorium.
UWAGA: zanim zaczniemy korzystać z tego laboratorium, prosimy o zrozumienie, że zmienimy środowisko nauczania, aby poszerzać naszą wiedzę i możliwości. Teraz w przyszłości możesz wrócić do wbudowanych podręczników, ale znowu będziesz potrzebować więcej zasobów systemowych, jak wyjaśniono wcześniej.
Aby dzielić się danymi analitycznymi i zapewnić solidniejsze środowisko szkoleniowe, bracia Rodriguez opracowali zestaw notatników Jupyter przechowywanych na platformie Binderhub. Najpierw odwiedź https://threathunterplaybook.com/introduction.html. Po lewej stronie ekranu kliknij łącze Bezpłatny notatnik telemetryczny. Spowoduje to załadowanie strony notatnika Jupyter, która zawiera zestaw danych Mordoru i wszystkie analizy gotowe do nauki.

Następnie kliknij ikonę rakiety u góry ekranu i uruchom łącze Binder.
Uruchomienie notatnika Jupyter może zająć kilka minut, ale należy uzbroić się w cierpliwość. Po załadowaniu kliknij pierwszy blok kodu, a następnie kliknij przycisk Uruchom u góry lub naciśnij SHIFT-ENTER, aby uruchomić ten blok kodu i załadować wymagane biblioteki. Pamiętaj, że niektóre kroki w tej bibliotece zajmą trochę czasu. Po lewej stronie bloku kodu zobaczysz symbol postępu, [*], a po jego zakończeniu pojawi się liczba. Zanim przejdziesz dalej, pamiętaj o ukończeniu tych bloków kodu.
Koniecznie przeczytaj tekst wyświetlany nad każdym blokiem kodu aby zrozumieć to; następnie klikaj przycisk Uruchom lub naciskaj SHIFT-ENTER, aby wykonać kolejne bloki kodu, aż dojdziesz do bloku kodu Decompress Dataset. W chwili pisania tego rozdziału podczas pobierania danych Mordoru w notatniku pojawia się błąd i należy zmienić polecenie na następujący adres URL (przed uruchomieniem tego bloku należy potwierdzić jak poniżej):
![]()
Kontynuuj wykonywanie bloków kodu i komentarzy, aż dojdziesz do następnego kroku

Następnym blokiem kodu, który wykonujesz, jest Spark SQL, który wybiera rekordy z widoku tymczasowego apt29Host z kanału Sysmon/Operational, gdzie EventID = 1, ParentImage zawiera „%explorer.exe”, a Image (nazwa pliku) zawiera „%3aka3% ”. Informacje te pochodzą z naszego poprzedniego polowania, podczas którego odkryliśmy, że Pam kliknęła wygaszacz ekranu o tej nazwie. Zobaczmy, jak głęboko sięga ta królicza nora!
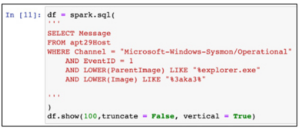
Ten kod zwraca rekord z wpisem dziennika w następujący sposób:

To powinno być już znajome. Idź dalej, uważnie studiując każdy krok, patrząc przez ramię Roberto Rodrigueza, który przygotował to dla Ciebie. Zobaczysz połączenie sieciowe, które znaleźliśmy wcześniej; zobaczysz także uruchomienie cmd.exe. Interesujące jest obserwowanie procesu w innym kierunku. Pamiętaj, że powiedzieliśmy wcześniej, że często zaczniesz od środka struktury MITRE ATT&CK, a następnie będziesz pracować w lewo i prawo, aby znaleźć przeciwnika. Zapytania będą proste, dopóki nie dojdziesz do „1.B.2. PowerShell”, gdzie znajduje się nasza pierwsza instrukcja łączenia.
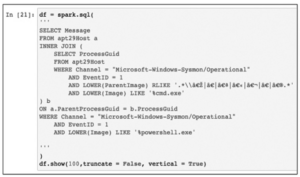
To powinno być już znajome. Idź dalej, uważnie studiując każdy krok, patrząc przez ramię Roberto Rodrigueza, który przygotował to dla Ciebie. Zobaczysz połączenie sieciowe, które znaleźliśmy wcześniej; zobaczysz także uruchomienie cmd.exe. Interesujące jest obserwowanie procesu w innym kierunku. Pamiętaj, że powiedzieliśmy wcześniej, że często zaczniesz od środka struktury MITRE ATT&CK, a następnie będziesz pracować w lewo i prawo, aby znaleźć przeciwnika. Zapytania będą proste, dopóki nie dojdziesz do „1.B.2. PowerShell”, gdzie znajduje się nasza pierwsza instrukcja łączenia.

To powinno być już znajome. Idź dalej, uważnie studiując każdy krok, patrząc przez ramię Roberto Rodrigueza, który przygotował to dla Ciebie. Zobaczysz połączenie sieciowe, które znaleźliśmy wcześniej; zobaczysz także uruchomienie cmd.exe. Interesujące jest obserwowanie procesu w innym kierunku. Pamiętaj, że powiedzieliśmy wcześniej, że często zaczniesz od środka struktury MITRE ATT&CK, a następnie będziesz pracować w lewo i prawo, aby znaleźć przeciwnika. Zapytania będą proste, dopóki nie dojdziesz do „1.B.2. PowerShell”, gdzie znajduje się nasza pierwsza instrukcja łączenia.
Istnieje kilka powodów, dla których Spark i Jupyter są potrzebne do usprawnienia naszej nauki. Chociaż Elasticsearch jest dobry, nie jest relacyjną bazą danych, więc okazuje się, że łączenia są kosztowne obliczeniowo. Łączenie to funkcja wspólna dla SQL, która pozwala nam łączyć dane w ramach zapytania, aby być bardziej przedmiotem naszych dochodzeń. Na przykład, gdybyśmy mieli dwa źródła danych, jedno z static_ip i nazwą_użytkownika, a drugie ze static_ip i nazwą_hosta, moglibyśmy je połączyć w następujący sposób. Lewe połączenie zwraca rekordy z lewego źródła z dopasowaniami z prawego źródła:
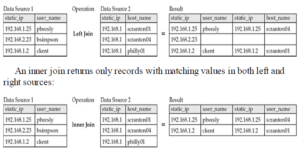
Pełne złączenie zewnętrzne zwraca rekordy, jeśli istnieje dopasowanie z któregokolwiek źródła:
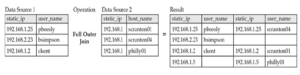
Złączenia te można wykonać za pomocą Apache Spark, wykorzystując dane z Elasticsearch, co jest szczególnie przydatne podczas polowania na zagrożenia, umożliwiając nam ulepszanie lub wzbogacanie naszych danych poprzez połączenie kilku źródeł danych. Zobaczymy, jak to się rozegra w następnym laboratorium.
Jak dotąd nauczyłeś się czołgać, chodzić, a następnie biegać (no cóż, może biegać) w poszukiwaniu zagrożeń. Teraz nauczmy się sprintu, korzystając z Poradnika łowcy zagrożeń autorstwa, jak się domyślacie, braci Rodriguez. Na razie odchodzimy od HELK. Do tego momentu mogliśmy korzystać ze środowiska DetectionLab, rozszerzonego o HELK, aby (1) ćwiczyć znajdowanie izolowanych ataków za pomocą skryptów AtomicRedTeam oraz (2) wykorzystywać zbiory danych Mordoru do ćwiczeń na bardziej wszechstronnych dane ataku. Teraz osiągnęliśmy limit naszego środowiska DetectionLab. Powodem jest jeden z wymaganych zasobów. Być może pamiętasz z rozdziału 8, że podczas instalacji HELK-a wybraliśmy 4. W tym kroku zainstalowano następujące elementy:
![]()
Ta selekcja (2) wymagała 5 GB pamięci RAM i to wszystko, co nam pozostało po zainstalowaniu reszty DetectionLab przy określonych wymaganiach systemowych wynoszących 16 GB pamięci RAM. Teraz, jeśli masz więcej niż 16 GB pamięci RAM dostępnej lub zainstalowanej w chmurze (wybierając większy system, np. Standard_D3_v2), możesz wybrać kolejny poziom 3:
![]()
Jak wskazano, ta wersja zawiera Spark i Jupyter, które są wymagane, aby przejść dalej w tym rozdziale. A co, jeśli nie masz takich wymagań systemowych i nie chcesz dodatkowych wydatków związanych z większą instancją w chmurze? Dbamy o Ciebie, więc nie martw się. W pozostałej części tego rozdziału wykorzystano podręcznik braci Rodriguez, Threat Hunter Playbook, wraz z internetowym środowiskiem wykonawczym, dzięki któremu możesz kontynuować naukę.