https://chacker.pl/
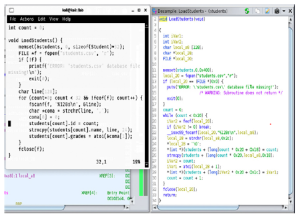
Ważne jest, aby zrozumieć, jak prawidłowo pracować i poruszać się po IDA Pro, ponieważ istnieje wiele domyślnych zakładek i okien. Zacznijmy od przykładu załadowania podstawowego pliku binarnego do IDA Pro jako pliku wejściowego. Podczas pierwszego ładowania programu myAtoi do IDA Pro pojawia się następujące okno:
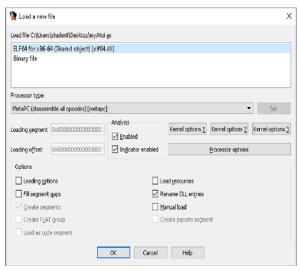
IDA Pro przeanalizował metadane pliku obiektowego i ustalił, że jest to 64-bitowy plik binarny ELF. IDA przeprowadza dużą część wstępnej analizy, takiej jak śledzenie przepływu wykonywania, przekazywanie podpisów technologii szybkiej identyfikacji i rozpoznawania bibliotek (FLIRT), śledzenie wskaźników stosu, analiza tabeli symboli i nazewnictwo funkcji, wstawianie danych o typach, jeśli są dostępne, oraz przypisanie nazw lokalizacji. Po kliknięciu OK IDA Pro przeprowadza automatyczną analizę. W przypadku dużych plików wejściowych analiza może zająć trochę czasu. Zamknięcie wszystkich okien i ukrycie paska narzędzi Nawigatora przyspiesza analizę. Po zakończeniu kliknięcie opcji Windows w opcjach menu i wybranie Resetuj pulpit przywraca układ do ustawień domyślnych. Gdy IDA Pro zakończy automatyczną analizę programu myAtoi, otrzymamy wynik pokazany na rysunku
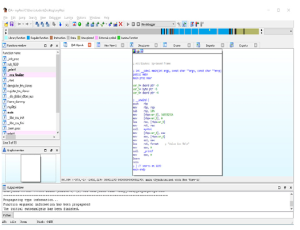
UWAGA Wiele funkcji i elementów przedstawiono na rysunku 5-1. Pamiętaj, aby wracać do tego obrazu, gdy będziemy przeglądać różne sekcje, funkcje i opcje.
Pasek narzędzi Nawigatora na rysunku zapewnia przegląd całego pliku wejściowego, podzielonego na różne sekcje.
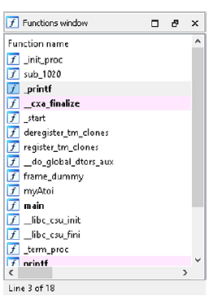
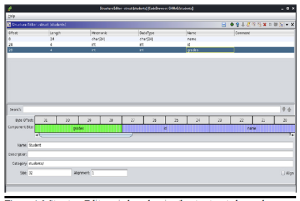
Każdy oznaczony kolorem obszar na pasku narzędzi można kliknąć, aby uzyskać łatwy dostęp do tej lokalizacji. W naszym przykładzie z programem myAtoi duża część ogólnego obrazu jest identyfikowana jako zwykłe funkcje. Oznacza to funkcje wewnętrzne i kod wykonywalny skompilowany do postaci binarnej, w przeciwieństwie do symboli zewnętrznych, które są zależnościami dynamicznymi, oraz funkcji bibliotecznych, które wskazywałyby statycznie skompilowany kod biblioteki. Okno Funkcje, pokazane na rysunku, zawiera listę nazw wszystkich funkcji wewnętrznych i zależności dynamicznych.
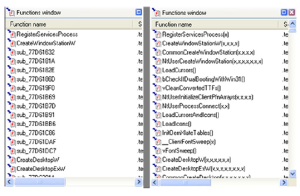
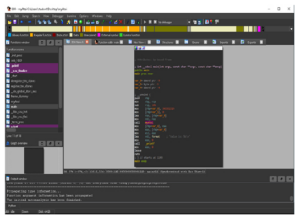
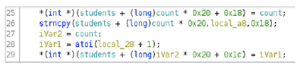
Dwukrotne kliknięcie wpisu powoduje wyświetlenie tej funkcji w głównym oknie widoku wykresu. Klawisz skrótu G umożliwia także bezpośrednie przejście do adresu. Jeśli w IDA Pro dostępna jest tabela symboli, wszystkie funkcje otrzymują odpowiednie nazwy. Jeśli informacja o symbolu nie jest dostępna dla danej funkcji, podaje się przedrostek podrzędny, po którym następuje przesunięcie względnego adresu wirtualnego (RVA), takie jak sub_1020. Poniżej znajduje się przykład sytuacji, w której tabela symboli nie jest dostępna, a kiedy jest dostępna. Poniżej okna Funkcje znajduje się okno Przegląd wykresu. . Jest to po prostu interaktywne okno przedstawiające całą aktualnie analizowaną funkcję. Okno danych wyjściowych na dole domyślnego układu IDA Pro pokazano na rysunku wraz z interaktywnym paskiem Pythona lub IDC.

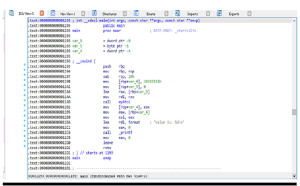
Okno Dane wyjściowe to miejsce, w którym wyświetlane są komunikaty oraz wyniki wprowadzonych danych polecenia za pośrednictwem IDA Python lub IDC. IDA Python i IDC zostały omówione w rozdziale 13. W naszym przykładzie ostatni wyświetlony komunikat brzmi: „Początkowa autoanaliza została zakończona”. Główne okno pośrodku domyślnego układu IDA Pro nosi nazwę IDA View-A w naszym przykładzie i pokazano na rysunku . To jest widok wykresu, który wyświetla funkcje i bloki w obrębie tych funkcji w rekurencyjnym stylu opadania. Naciśnięcie spacji w tym oknie powoduje przełączenie widoku z widoku wykresu na widok tekstowy, jak pokazano na rysunku. Widok tekstowy to bardziej liniowy sposób patrzenia na demontaż. Ponowne naciśnięcie spacji przełącza pomiędzy dwiema opcjami widoku. Na rysunku pokazano główną funkcję i jest tylko jeden blok kodu. Informacje o typie są wyświetlane u góry funkcji, po nich następują zmienne lokalne i dezasemblacja.

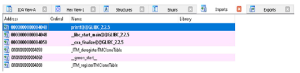
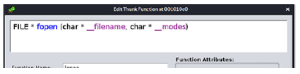
Rysunek przedstawia zakładkę Importy. To okno wyświetla wszystkie dynamiczne zależności pliku wejściowego od kodu biblioteki. Najwyższy wpis na liście to funkcja printf. Obiekt współdzielony zawierający tę funkcję jest wymagany do działania programu i musi zostać mapowany do procesu w czasie wykonywania. Nie pokazana jest karta Eksporty. W tym oknie wyświetlana jest lista normalnie dostępnych wyeksportowanych funkcji i skojarzonych z nimi adresów. Z tej sekcji korzystają obiekty współdzielone i biblioteki dołączane dynamicznie (DLL).